Abstract
Current diffusion-based video editing primarily focuses on structure-preserved editing by utilizing various dense correspondences to ensure temporal consistency and motion alignment. However, these approaches are often ineffective when the target edit involves a shape change.
To embark on video editing with shape change, we explore customized video subject swapping in this work, where we aim to replace the main subject in a source video with a target subject having a distinct identity and potentially different shape.
In contrast to previous methods that rely on dense correspondences, we introduce the VideoSwap framework that exploits semantic point correspondences, inspired by our observation that only a small number of semantic points are necessary to align the subject's motion trajectory and modify its shape. We also introduce various user-point interactions (e.g., removing points and dragging points) to address various semantic point correspondence. Extensive experiments demonstrate state-of-the-art video subject swapping results across a variety of real-world videos.
Method
- align the subject motion trajectory and change the subject shape.
- transfer across semantic and low-level changes.
VideoSwap: Set up semantic points: Motivated by our observations, we introduce semantic point correspondence in the VideoSwap framework. We first set up user-defined semantic points by
- extracting their trajectory and semantic embedding.
- registering them on the source video.
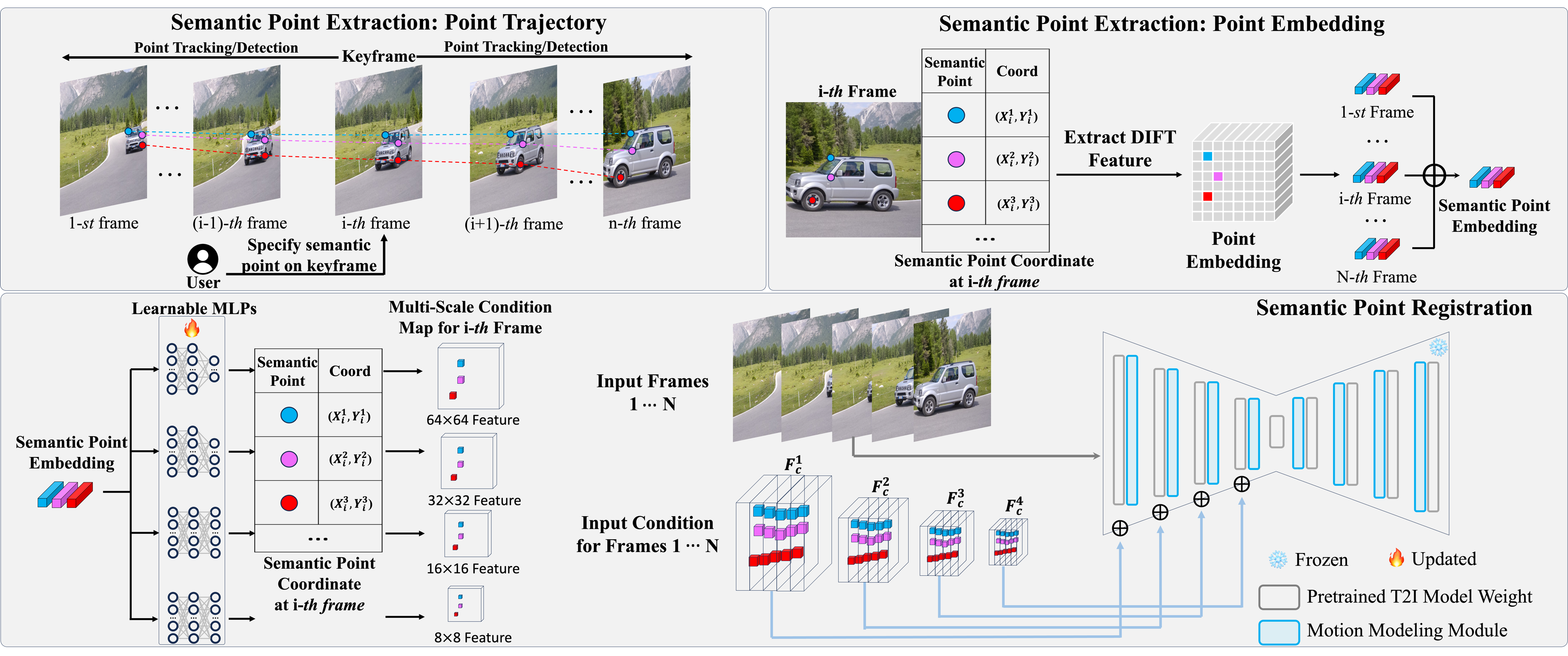
VideoSwap: Guide the motion trajectory by semantic points: After setting up semantic points, we guide the motion trajectory of swapped targets with the following three types of correspondence:
- One-to-One Point Correspondence.
- Partial Point Correspondence.
- Point Correspondence with Shape Morphing.
Results (Click for More Results)
|
| Source Video | kitten -> V catA | kitten -> V catA | kitten -> V catA |
|---|---|---|---|
| Source Video | airplane -> V jet | airplane -> helicopter |
|---|---|---|
Keyframe  Source Prompt: "A black swan swimming in a pond." Target Swap: black swan -> duck |
Source Point Trajectory | Result Guided by Source Point Trajectory |
|---|---|---|
| Dragged Point Trajectory | Result Guided by Dragged Point Trajectory | |
Keyframe  Source Prompt: "A silver jeep driving down a curvy road in the countryside." Target Swap: silver jeep -> V carA |
Source Point Trajectory | Result Guided by Source Point Trajectory |
| Dragged Point Trajectory | Result Guided by Dragged Point Trajectory | |
Comparison (Click for More Comparison)

| Source Video | VideoSwap (Ours) | Rerender-A-Video | TokenFlow |
|---|---|---|---|
| Text2Video-Zero | StableVideo | Tune-A-Video | FateZero |
|---|---|---|---|
| Source Video | VideoSwap (Ours) | Rerender-A-Video | TokenFlow |
|---|---|---|---|
| Text2Video-Zero | StableVideo | Tune-A-Video | FateZero |
|---|---|---|---|
BibTeX
@article{gu2023videoswap,
author = {Gu, Yuchao and Zhou, Yipin and Wu, Bichen and Yu, Licheng and Liu, Jia-Wei and Zhao, Rui and Wu, Jay Zhangjie and Zhang, David Junhao and Shou, Mike Zheng and Tang, Kevin},
title = {VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence},
journal = {arXiv preprint},
year = {2023},
}